개발 로그 ③
개요
다양한 딥러닝 모델 경험, 성능 비교를 위해 Food 101 데이터셋을 활용한 101개 음식 이미지 분류 모델을 구현했습니다.
이 작업은 Vision Transformer모델로 구현했으며, 총 101,000장의 이미지를 학습, 검증, 테스트 데이터셋으로 분할하여 학습 및 성능 평가를
진행했습니다.
사용 기술
데이터 수집 및 처리 과정
ㆍ 총 101,000장의 Food 101 공개 데이터셋 사용
ㆍ 데이터 증강 → HorizontalFlip, Rotation(20°), ColorJitter, Normalize
ㆍ 데이터 분할 → Train (75,750장), Test (25,250장)
모델 구조
ㆍ Patch Embedding
└ 입력 Shape :
(B, C, H, W) → 출력 Shape: (B, 14×14, 768)
ㆍ Class Token 추가 & Position Embedding 적용
ㆍ 12 × [Encoder Block]
└ 12 ×
[MultiheadAttention → Skip Connection → MLP → Skip Connection]
ㆍ MLP Head
└ Class
Token을 이용해 최종 클래스 예측
학습 설정 및 결과
ㆍ Model : Vision Transformer (ViT-Base, Patch Size = 16, Image
Size = 224)
ㆍ Loss Function : CrossEntropyLoss
ㆍ Optimizer : AdamW (learning rate = 0.00003, weight decay =
0.00001)
ㆍ Scehduler : ReduceLROnPlateau (patience = 5)
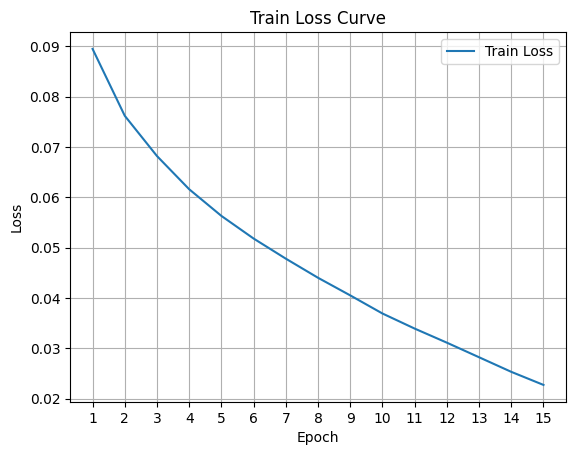
ㆍ Epochs : 15회
ㆍ Accuracy : 65.44%
ㆍ Training Curve :
고찰
ㆍ 초기 모델 구성
- ViT
Model 직접 구현
- Train / Val / Test 분할 데이터셋
구성
- 20~30 Epoch 학습 도중 과적합 발생 →
정확도 : 약 50%
ㆍ 개선 과정 ①
- timm
라이브러리의 ViT-Base 모델로 전환
- 데이터 증강 수정:
└ MixUp 기법 적용 후 재학습 (강화) →
MixUp 및 RandomRotation 제거 후 재학습 (축소)
- 동일하게 20~30 Epoch 학습 도중 과적합
발생 → 정확도 : 약 50%
ㆍ 개선 과정 ②
- Validation
Dataset 제거
- 최초 데이터 증강 구성으로
복귀
ㆍ 최종 결과
- 정확도 :
65.44%
ㆍ 느낀 점
- 검증 데이터
분할의 악영향 → 원인 불명
└ 모델의 높은 학습시간, 제한적인 PC 환경으로
충분한 실험 반복이 어려움
└ 검증데이터 분류 과정에서 클래스간 불균일한 데이터
분류, 학습데이터의 축소 등을 의심