개발 로그 ①
개요
딥러닝 모델의 작동 원리 및 구조를 이해하기 위해, CIFAR-10 데이터셋을 활용한 10개 클래스의 이미지 분류 모델을 구현했습니다.
이 작업은 기본적인 CNN 레이어들로 구현했으며, 약 60,000장의 이미지를 학습, 검증, 테스트 데이터셋으로 분할해 학습 및 성능 평가를 진행했습니다.
사용 기술
데이터 수집 및 처리 과정
ㆍ 총 60,000장의 (32×32px) CIFAR-10 공개 데이터셋 사용
ㆍ 데이터 증강 → HorizontalFlip, Rotation(15°), Normalize
ㆍ 데이터 분할 → Train (45,000장), Validation (5,000장), Test (10,000장)
모델 구조
ㆍ 3 × [Conv → BatchNorm → ReLU → MaxPool] 블록 구성
└
Conv1 : 3
→ 64, Conv2 : 64 → 128, Conv3 : 128 → 256
ㆍ FC1 (4096→64) → ReLU → Dropout(0.2)
ㆍ FC2 (64→10) → 최종 클래스 예측
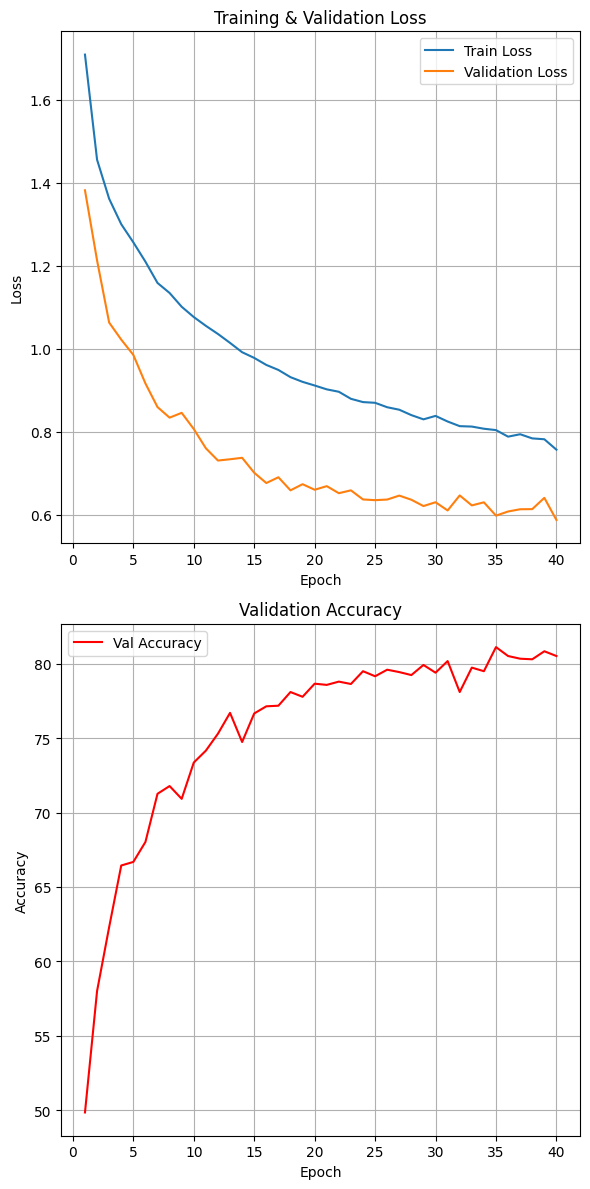
학습 설정 및 결과
ㆍ Loss Function : CrossEntropyLoss
ㆍ Optimizer : Adam (learning rate = 0.001)
ㆍ Epochs : 40회
ㆍ Accuracy : 79.81%
ㆍ Training Curve :
고찰
ㆍ 초기 모델 구성
- Train /
Test 데이터셋만 구성
- CNN 레이어: 2개
- 데이터 증강: 정규화(Normalize)만
적용
- BatchNorm / Dropout:
미적용
- 정확도 : 약 70%
ㆍ 개선 과정 ①
- Validation
데이터셋 추가
- 데이터 증강 추가: HorizontalFlip,
Rotation (90° Fixed)
- CNN 레이어 3개로 확장
- BatchNorm, Dropout(0.2)
도입
- 정확도 : 약 20%
ㆍ 개선 과정 ②
- 데이터 증강
수정: HorizontalFlip, Rotation(15°)
- CNN 레이어 3개로
확장
ㆍ 최종 결과
- 정확도 :
79.81%
ㆍ 느낀 점
- 검증 데이터의
필요성
- BatchNorm과 Dropout의 중요성
- CNN Layer가 추가될수록 더 디테일한
부분까지 학습이 이뤄짐
- 무분별한 데이터 증강 추가가 반드시 성능 향상으로
이어지는 것은 아님